Обработка исключительных ситуаций (Exceptions).
Как правильно ловить исключения.
Рассмотрим следующий пример кода:
f(){
try{
работа с сетью;
}
catch(NetworkException){
printf("NetworkError");
}
}
Например, исключение могло произойти, когда мы работали с сетью, и соединение оборвалось, или вторая сторона не выполнила протокол.
Что плохого в этом коде:
- Функция
f берёт на себя слишком много.
Ей не хватает мощи, чтобы обработать последствия ошибки, это не её контекст.
- Функция
f делает слишком много предположений.
В частности, она делает предположение о том, что клиент, который вызывает эту функцию, имеет текстовый интерфейс. Мы могли применять графическое приложение, а сообщение выводится в консоль. В этом случае пользователь не увидит сообщение об ошибке.
Корректно решить эти проблемы можно было бы двумя способами:
- Не ловить исключение вообще, чтобы оно летело дальше.
- Предпринять какие-либо действия и уведомить вышестоящие функции о том, что исключение произошло.
Например, это можно сделать таким образом:
f(){
try{
работа с сетью;
}
catch(NetworkException e){
закрыть соединение;
throw e;//уведомляем вышестоящие функции
}
}
Накладные расходы на исключения.
Допустим, есть цепочка функций:
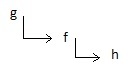
И в этой цепочке есть место, где ловят исключение, предпринимаются какие-то действия, и исключение летит дальше. Для примера возьмём функцию f, описанную раньше.
Код, в котором мы ловили исключение, можно написать двумя способами:
catch(NetworkException e){
...
throw e;
}
catch(NetworkException &e){
...
throw;
}
Есть ли разница в этих двух записях?
Для лучшего понимания рассмотрим ещё совсем неправильный пример:
3. try{
NetworkException e;
throw &e;
}
catch(NetworkException *e){
...
}
В последнем примере в конце области видимости блока try объект e будет уничтожен, и мы будем ловить непонятно что. Можно, конечно, выделять память динамически, но тогда кто-то где-то должен будет её освободить. Это неудобно.
Что же сделали разработчики механизма исключений, чтобы избавиться от этой ситуации?
Вернёмся к нашей цепочке функций g->f->h. Если функция h бросила исключение, то нужно следовать по стеку, находя места, где есть обработчики, и вызывать их.
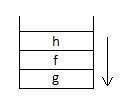
Следуя от одного stackframe'а к другому, всегда вызывается конструктор копирования, чтобы не было проблем с областями видимости. Таким образом, когда исключение идёт через стек, происходит копирование этого исключения.
Первый способ записи блока catch менее эффективен, чем второй, поскольку в нём на два вызова конструктора копирования больше. Один раз конструктор копирования вызывается, так как фактически происходит передача параметра у catch, а второй раз - когда мы указываем параметр для throw.
Во втором способе мы передаём объект по ссылке, поэтому конструктор копирования не вызывается. А throw без указания конкретного объекта означает проброс исключения, которое пришло, без создания копии.
Когда exception распространяется по стеку, например, при переходе от f к g, нужно как-то определить, есть ли в g catch, и подходит ли он для данного исключения. Ради этого компилятор во время работы генерирует специальный код, и в stackframe'е хранится больше информации: помимо адреса возврата, параметров функции и локальных переменных там хранится информация о всех catch'ах данной функции, чтобы во время раскручивания стека (stack unwinding - процесс прохода вверх по стеку) можно было понять, есть у этой функции обработчики или нет, и проверить, если обработчик есть, подходит ли тип летящего исключения.
Выводы:
- Из-за копирований программа с использованием исключений медленнее, чем программа без них.
- Программа с использованием исключений занимает больше места, так как компилятор генерирует больше кода.
Зачем в С++ сделали механизм исключений.
Мы говорили о том, что исключения тем хороши, что с их помощью может быть передана информация об ошибке. В языке С была такая возможность.
Рассмотрим следующий пример:
#include ‹csetjmp›
class Bar{
private:
char *a;
public:
Bar(){
a = new char[100];
}
~Bar(){
delete[] a;
}
};
jmp_buf buf;
void foo(){
Bar b;
работа с сетью;
if (error){
longjmp(buf, 42);
}
}
int main(){
if (setjmp(buf) == 0){
foo();
}
else{
...
}
...
}
Вкратце, setjmp и longjmp - это функции из языка С. Они нужны для действия, похожего на то, что происходит с исключениями. А именно, чтобы можно было пройти через цепочку вызовов функций, то есть сделать stack unwinding.
Опишем действия этих функций поподробнее.
Что делает функция setjmp:
Состояние системы (то есть ссылка на то место, где процесс сейчас выполняет команду) сохраняется в buf. Грубо говоря, это счётчик команд. Когда функция setjmp вызывается в первый раз, она возвращает 0.
Функция longjmp позволяет продолжить выполнение процесса с того места, где было запомнено состояние счётчика команд. В приведённом примере после вызова этой функции выполнение продолжится с проверки возвращаемого значения функции setjmp на равенство нулю. При этом возвращаемым значением setjmp(buf) будет второй параметр функции longjmp. В нашем случае если в функции foo произойдёт ошибка, то возвращаемое значение функции setjmp станет равным 42, и начнётся выполнение другой ветки инструкции if.
У этого механизма есть одна проблема - нужно освобождать память. На стеке лежат локальные переменные, в том числе и объекты. А объекты это нечто, что могло в конструкторе навыделять ресурсов (памяти, файлов, блокировок и т.д.). Когда происходит исключительная ситуация, мы двигаемся вверх по стеку. При этом нам нужно, чтобы у всех объектов, которые сейчас лежат на стеке, вызывались бы деструкторы (в нашем примере это объект b). Но механизм с setjmp и longjmp пришёл из языка С, он ничего не знает про деструкторы. Вот почему появился механизм исключений.
Замечание: если в программе нет ни одного обработчика на данный тип исключения, то исключение вызывает функцию terminate, которая вызывает функцию abort (это функция из языка С). Функция abort в Unix'е аварийно завершает программу и выводит сообщение на экран.
Исключения в деструкторах.
Допустим, мы хотим сделать в программе обработку ошибок с помощью исключений, и у нас имеется такой класс:
class NetworkConnection{
NetworkConnection(){
...
}
~NetworkConnection(){
работа с файлами на C++;
}
...
}
Что плохого тут может произойти?
Если произойдёт исключительная ситуация, то когда будет проводиться stack unwinding, в каком-то деструкторе может произойти ещё одно исключение, а старое будет забыто. И мы увидим сообщение об одном exception'е (например, "ошибка в работе с файлами"), а ошибка изначально произошла по другой причине (например, "ошибка в работе с сетью"). Механизм исключений поддерживает состояние только одного исключения при раскручивании стека.
Чтобы таких ситуаций не возникало, если в деструкторе кидается exception, механизм раскручивания стека вызывает функцию terminate.
Деструкторы не должны кидать исключения! А если всё-таки в деструкторе приходится работать с чем-то, что может кинуть исключение, то можно подавить его таким образом:
~NetworkConnection(){
try{
работа с файлами на C++;
}
catch(...){//Тут поймается новый exception, а старый будет лететь дальше.
}
}
Исключения в конструкторах.
Представим, что мы пишем приложение "адресная книга" для мобильных телефонов. Одна запись включает в себя несколько полей: имя, телефон (а к некоторым записям могут быть привязаны и более сложные объекты: изображение, мелодия).
class Image{
...
}
class AudioTrack{
...
}
class BookEntry{
private:
std::string myName;
std::string myPhone;
Image *myImage;
AudioTrack *myAudio;
public:
BookEntry(std::string name, std::string phone = "",
imageName = "", trackName = ""){
myName = name;
myPhone = phone;
if (imageName != ""){
myImage = new Image(imageName);
}
if (trackName != ""){
myAudio = new AudioTrack(trackName);
}
}
~BookEntry(){
delete myImage;
delete myAudio;
}
}
В С++ есть такая особенность: у не до конца созданных объектов деструктор не вызывается.
Допустим, исключение произошло в этом месте:
myAudio = new AudioTrack(trackName);
Причин может быть несколько:
- указали не тот файл
- тип файла не подходит
- не хватило памяти для
new
- что-то ещё...
При раскручивании стека деструктор BookEntry вызван не будет. Так решили сделать, поскольку в этой ситуации деструктору сложно будет определить, какую часть нужно освободить, а какую не нужно, потому что ресурсы могут быть не такие простые, как new (например, работа с сетью или подключение к базе данных). Нужно было бы писать много дополнительного кода, чтобы понять, какую часть освобождать.
Это плохо тем, что мы не можем теперь полагаться на очистку того, что выделилось в конструкторе. Корректнее было бы написать конструктор так:
BookEntry(std::string name, std::string phone = "",
imageName = "", trackName = ""){
try{
myName = name;
myPhone = phone;
if (imageName != ""){
myImage = new Image(imageName);
}
if (trackName != ""){
myAudio = new AudioTrack(trackName);
}
}
catch(...){
delete myImage;
delete myAudio;
throw;
}
}
Вывод:
Поскольку в С++ решили ,что у объектов, которые не до конца инициализированы, деструктор не вызывается, программистам нужно прикладывать дополнительные усилия по работе с ресурсами, которые выделяются.
RAII.
RAII = Resource Acquisition Is Initialization ("Взятие ресурса должно делаться через инициализацию").
Рассмотрим такую ситацию: мы пишем программу для ветеринарной службы. В текстовом файле хранятся данные о животном, в частности, о его возрасте. Раз в месяц доктор запускает программу, и на экран выводятся те животные, которым пришло время делать прививку.
К примеру, файл состоит из записей. Первый байт отвечает за то, кошка это или собака.
void process(std::istream f){
while (f){
Animal *pA = read(f);
pA->process();
delete pA;
}
}
Как действует функция read: читаем запись в файле. В зависимости от первого байта создаём объект класса Cat или Dog, а потом возвращаем указатель на созданный объект.
И пусть где-то снаружи вызывается функция process:
try{
process(...);
}
catch(ios::failure){
Window.show("База повреждена");
}
Если исключение произойдёт в методе pA->process(), то не будет вызван delete pA, мы сразу начнём разматывать стек.
RAII говорит о том, что все выделения памяти надо делать внутри какого-нибудь объекта или класса, поскольку при раскручивании стека вызываются деструкторы объектов. Таким образом, нужно "обернуть" выделение памяти. Для этого можно использовать "умные указатели".
Можно, конечно, обойтись и без этого. Можно написать так:
try{
Animal *pA = read(f);
pA->process();
delete pA;
}
catch(...){
delete pA;
}
Но это некрасиво с точки зрения стиля. Здесь будет два очищения памяти: одно "честное" - когда не происходит ошибки, а другое - когда происходит исключительная ситуация.
Метод process с использованием "умных указателей" будет выглядеть так:
void process(std::istream f){
while (f){
std::auto_ptr pA(read(f));
pA->process();
}
}
Теперь очищение памяти будет проводиться автоматически в деструкторе.
Спецификация исключений.
Как узнать, что функция бросает исключения? Можно почитать документацию. Но ещё в С++ есть нотация, которая позволяет написать в объявлении функции, какие исключения функция может бросать.
void f() throw A,B{
...
}
Компилятор пытается контролировать, действительно ли в f и функциях, которые вызывает f, нет ни одной строчки throw C;. Но это сложно, и компилятор такую проверку делать не умеет, поэтому проверка делается частично.
Аналогично, как есть функция terminate(), есть функция unexpected(). Она вызывается во время выполнения программы, если нарушается декларация функции, то есть она вызывается, если в функции бросается что-то, что не описано. Unexpected вызовет terminate, и программа аварийно завершится.
Таким образом, чтобы никогда не выскочил unexpected, нужно писать очень аккуратно и указывать все исключения, которые могут быть брошены. Но это сложно сделать, поскольку мы можем использовать какие-то библиотеки, а тогда мы должны будем указать и все исключения у библиотечных функций. Это довольно муторно, поэтому данной нотацией почти никто не пользуется.
В ‹stdexcept› описаны исключения стандартной библиотеки. Если туда заглянуть, то можно увидеть, что там, вообще, не пишется throw, и, как правило, эти исключения сложно обработать.
Гарантии при работе с исключениями.
Если мы используем в программе механизм исключений, то хотелось бы, чтобы выполнялось следующее правило: если при работе с объектом в нём произошло исключение, то объект должен сохранить состояние, в котором он находился до того, как произошло исключение. Другими словами, не хотелось бы, чтобы после exception'а объект "испортился".
Рассмотрим такой пример:
std::stack
template T stack::pop(){
if (count == 0){
throw logic_error("stack underflow");
}
else{
return data[--count];
}
}
Что здесь может произойти плохого? Дело в том, что класс шаблонный. Когда делается return, вызывается конструткор копирования, в котором тоже может произойти исключение. Если оно случится, то мы потеряем элемент, поскольку счётчик count уже будет изменён.
Поэтому разработчики сделали две функции: top() и pop().
T top(); - возвращает элемент.
void pop(); - перемещает указатель.
Соответственно, для правильной работы с std::stack программист сначала должен вызвать функцию top(), а функцию pop() он должен вызвать только в том случае, если исключение не произошло, чтобы не разрушить состояние объекта.
Какие бывают гарантии:
Не кидать исключения вообще (no-throw guarantee).
Данная гарантия означает, что операция, которую мы собираемся выполнить, не бросит исключение. К примеру, функция erase() в std::list обеспечивает эту гарантию, а в std::vector та же функция обеспечивает эту гарантию только если конструктор копирования или оператор присваивания класса, используемого в данном векторе, не бросает исключений (иначе будет обеспечена лишь базовая гарантия, о которой будет написано чуть позже). Это самая сильная гарантия, её труднее всего обеспечить.
Строгая гарантия (strong guarantee).
По сути, это некоторый аналог транзакций: в случае возникновения исключений все изменения, произведённые возбудившей исключение функцией, будут откачены (rollback). Таким образом, мы возвращаемся в то же самое состояние, что и до исключения.
В примере с std::stack правильное использование функций top() и pop() обеспечивает строгую гарантию, а приведённая ниже реализация функции pop() является примером нарушения этой гарантии.
template T stack::pop(){
if (count == 0){
throw logic_error("stack underflow");
}
else{
return data[--count];
}
}
Базовая гарантия (basic guarantee).
Не всегда можно вернуться в то же состояние, что было до того, как произошло исключение. Например, мы могли выводить на экран какие-то сообщения. Мы не сможем их уже убрать, если произойдёт исключение. Базовая гарантия означает, что после обработки исключения мы возвращаемся в непротиворечивое состояние, и не происходит утечек памяти.
К примеру, любая функция из STL обеспечивает хотя бы базовую гарантию. Ещё одним примером может служить функция pop(), которую мы описали выше. А в следующем примере не обеспечивается даже базовая гарантия:
void doSomething(T & t){
t.integer += 1; // no-throw
X *x = new X(); // basic: конструктор X или оператор new могут бросить исключение
t.list.push_back(*x); // strong
delete x; // no-throw: поскольку деструкторы не должны бросать исключений!
}
Хоть каждая из операций, проведённых в методе doSomething, и обеспечивает какую-то из гарантий, но если в методе push_back возникнет исключительная ситуация, то произойдёт утечка памяти, поскольку оператор delete не будет вызван.
На этом мы заканчиваем обсуждение основных проблем, связанных с механизмом исключений. Далее мы поговорим о некоторых вещах, связанных с тестированием программ.
Тестирование.
Asserts.
Когда продукт готовится к поступлению в продажу, то желательно оставить обработку только для внешних ошибок (кончилось место на диске, исчезло сетевое соединение, программой неправильно пользуются и т.д.), а всё остальное желательно отловить.
Хотелось бы, чтобы можно было отловить ошибки при тестировании, то есть в процессе разработки программы можно запускать тестирование каких-то неприятных ситуаций, и если произойдёт ошибка, то будет показано соответствующее сообщение. Такой механизм называется assert.
Есть такой термин: инвариант. В данном контексте инвариант это такое условие, которое должно соблюдаться в процессе работы класса (либо условие, которое было выполнено до вызова функции, должно быть выполнено и после вызова, и т.п.). Если это условие не соблюдается, то программа должна аварийно завершиться, и на экран должно быть выведено сообщение об ошибке.
Как работает assert? Он получает на вход какое-то выражение. Например:
View(Model *m){
assert(m != NULL);
...
}
Если когда-нибудь произойдёт ситуация, в которой View будет интерпретироваться пустой моделью, то программа аварийно завершится, и на экран будет выведена информация о том файле и той строчке, где это произошло.
Чтобы использовать assert, нужно подключить хедер ‹cassert›. Фактически мы добавили в код дополнительную проверку с целью отловить некоторые ошибки на этапе тестирования программы. Когда с ней будет работать пользователь, все assert'ы уже должны быть соблюдены, поэтому assert сделан в виде макроса. Если написать #define NDEBUG, то все assert'ы, грубо говоря, заменятся символом ';'. Таким образом, в программе в том виде, в котором она идёт к пользователю, уже не будет этого дополнительного кода. Чтобы не писать во всех файлах #define NDEBUG, можно указать специальный ключ компилятору:
gcc -DNDEBUG
Assert'ы нужны для собственной проверки, тестирования, а не для обработки ошибок, как это делает механизм исключений! К примеру, если мы разрабатываем класс, то для всех public методов можно использовать механизм исключений, а для private методов использовать assert'ы.
TDD.
TDD = Test-driven development (Разработка через тестирование). Это техника программирования, при которой модульные тесты для программы или её фрагмента пишутся до самой программы и, по существу, управляют её разработкой. Таким образом, на каждом этапе разработки имеются готовые тесты, и мы можем проверить, успешно ли программа их проходит.
Немного о стратегиях разработки.
Есть множество стратегий разработки программного обеспечения. Мы не будем вдаваться в подробности, а рассмотрим два противоположных конца стратегий разработки.
Самой первой стратегией является Waterfall ("водопад"). В ней процесс разработки представляется в виде водопада:
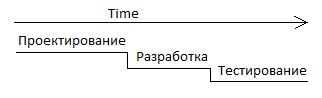
Обычно на этапе проектирования мы не обладаем всеми знаниями о задаче. В процессе программирования у нас будет появляться новая информация. Поэтому такой подход неудобен.
В другом подходе (это уже ближе к Agile) процесс разработки ведётся итеративно.

Идея данного подхода состоит в том, что на каждом таком участке мы имеем законченный работающий прототип. Возможно, что-то в нём работает медленно, и в каких-то случаях он валится, но у нас есть какая-то рабочая версия. В конце этапа при работающей программе улучшается её структура. Это называется рефакторингом (refactoring).
Как здесь могут помочь тесты.
Пусть мы улучшили на каком-то этапе наш код. Нам нужно проверить, работает ли после этих изменений наша программа. Вообще, у тестов есть две цели:
- Проверить, что программа работает.
- Проверить прежние возможности (проверяется такой факт: когда мы улучшили внутренности, с точки зрения внешнего пользователя класс ведёт себя так же).
Пример: Мы работаем с SVN. Сначала мы сделали update и начали работать. В это время кто-то сделал commit. Потом мы закончили работу и решили отправить свою версию. Что нам нужно сделать:
- Сделать
update.
- Скомпилировать программу, чтобы проверить, что она работает.
- Запустить тесты, убедиться, что все они проходят.
- Сделать
commit.
Эта техника (TDD) часто применяется в экстремальном программировании, но, вообще, ей пользуются редко.
Практическое задание.
К примеру, у нас есть класс Date.
Date myDay(1951, 10, 1);
test(myDay.getYear() == 1951);
test(myDay.getMonth() == 10);
Хотим написать функцию test, которая будет проверять состояние объекта. Если какой-то тест не прошёл, то должно быть выведено сообщение на экран, в котором были бы указаны файл, строчка и выражение, которое не выполнилось. Ещё должны быть счётчики успешных и неуспешных тестов и функция testReport, которая выводила бы на экран общее число тестов, а также количество успешных и неуспешных тестов. В такой реализации нужны глобальные переменные, поэтому нужно написать класс Test. Когда нужно тестировать класс Date, наследуемся от класса Test как DateTest и перекрываем функцию run(), в которой будет код, описанный выше. Чтобы выводить на экран имя файла, строчку и выражение, которое не выполнилось, можно реализовать test в виде макроса. Идея такая:
#define test(a) ...
#a //подставится содержимое a как строчка
__FILE__ //подставится имя файла как строчка
__LINE__ //подставится номер строчки
main.cpp
DateTest t;
t.run();
t.report();
Вместо класса Date использовать какой-нибудь свой класс из проекта академии по практике.