0 Про идею файлов в ОС UNIX
0.1 Концепция: все есть файл
Интуитивное определение файла звучит примерно так. Файл -- именованная область на жестком диске.
На самом деле с точки зрения ОС UNIX это совсем не так. В ОС UNIX файл -- очень удобная абстракция.
С точки зрения UNIX файлом называется "что-нибудь", из чего можно считывать информацию или во что можно записывать информацию.
Файлы это:
- Файлы в обычном смысле: файлы, которые хранятся на жестком диске (можно считывать из них и запиcывать в них информацию);
- Экран монитора: файл, в который можно выводить информацию (отобразится на экране монитора);
- Клавиатура: файл, из которого можно считывать информацию;
- Принтер: файл, в который можно выводить информацию (печать текста);
- Модем: файл, из которого можно считывать информацию и в который можно записывать информацию (обмен информации по сети);
Файл -- это всё, что предназначено для ввода или вывода информации.
С этой точки зрения файлы бывают разными: принтер может только выводить информацию, а клавиатура -- только вводить.
У такого рода файлов есть много особенностей. У файла на жестком диске есть понятие конца файла.
Мы можем его считывать до тех пор, пока он не кончится. Тогда как у клавиатуры нет конца.
0.2 Разделение понятий файла и названия
Неправильно думать, что между сущностями "файл" и "название файла" есть взаимно однозначное соответствие.
Можно привести аналогию из жизни: если представить, что файл -- это банка с некоторым содержимым, то название файла -- это этикетка на этой банке.
Логично предположить, что у банки может быть несколько этикеток.
С точки зрения UNIX:
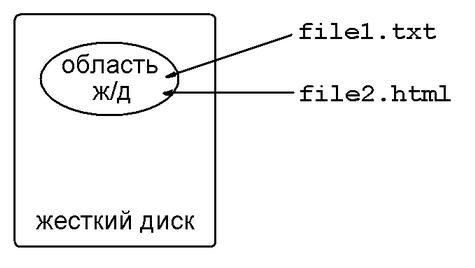
Правильно говорить, что у названия есть файл. И наоборот: неправильно говорить, что у файла есть название.
Никакого эффективного способа узнать имя файла не существует (но можно перебрать все файлы файловой системы).
0.3 Функции link и unlink
Пусть есть файл file1.txt. Для его удаления используется функция:
int unlink(const char* filename);
Эта функция не всегда удаляет файл (с жесткого диска), а только удаляет "этикетку" этого файла.
Если есть другая "этикетка" этого файла, то файл останется на жестком диске; просто у него уже не будет этой "этикетки".
Файл знает, сколько у него таких "этикеток" (есть специальный счетчик).
И если этот счетчик стал равен нулю, то функция удаляет файл с жесткого диска. В ОС Windows эта функция всегда удаляет файл.
Парная функция к этой функции:
int link(const char* filename1, const char* filename2);
Эта функция создает еще одну "этикетку" для этого файла и прибавляет к значению счетчика "этикеток" единицу.
1 Ввод и вывод, язык C, структура FILE
1.1 Чтение и запись: printf и scanf
Всем хорошо известная функция printf:
printf("Hello!") -- печать текста на экран;
printf("N = %d", N) -- форматированный вывод на экран: вывести число N в десятичной записи;
printf("N = %x", N) -- форматированный вывод на экран: вывести число N в шестнадцатеричной записи;
Аналогично парная функция scanf:
scanf("%d", &N) -- считывание с клавиатуры значения переменной N в десятичной записи;
char *ptr = new char[10];
scanf("%s", ptr); -- считывание с клавиатуры строки в массив *ptr
Тут могут возникать различные проблемы.
-
Проблема безопасности:
char *ptr = new char[10];
scanf("%s", ptr);
Тут налицо потенциальная проблема переполнения буфера (в данном примере в буфере всего 10 байт).
Никогда не следует пользоваться scanf'ом для чтения строк.
scanf + "%s" -- запрещенная комбинация!
-
Форматная строка не компилируется: она будет разбираться в момент исполнения программы.
Это обозначает проблему быстродействия.
scanf -- не предназначен для чтения большого количества информации.
Аналогично printf -- тоже сравнительно медленный (однако существенно быстрее, чем scanf).
-
Проблема безопасной работы со стеком:
printf("%d %d", N);
Проблема состоит в том, что форматная строка "%d %d" будет проанализирована в момент исполнения.
В данном случае произойдет ошибка при работе со стеком: во время исполнения будет взят лишний int.
Перечисленные недостатки означают, что использование функций printf и scanf небезопасно и малоэффективно.
Существенным плюсом этих функций является возможность простого форматированного ввода и вывода.
1.2 Чтение и запись файлов: FILE*, fopen, fprintf, fscanf
Есть несколько способов работы с файлами c использованием языков C и C++.
Самый распространенный связан со структурой FILE (это не класс, потому что сущность языка C).
Эта структура определена в заголовочном файле стандартной библиотеки <stdio.h>.
Размер этой структуры и ее поля зависят от ОС и от версии компилятора.
Поэтому никто не пользуется структурой FILE. Обычно пользуются указателем на эту структуру:
FILE*. Например:
FILE *f = fopen("file1.txt", "r");
fopen -- функция из стандартной библиотеки. Первый параметр -- имя файла (в текущем каталоге).
Второй параметр задает режим открытия файла; в данном случае "r" означает, что файл будет открыт только для чтения.
Эта функция возвращает ненулевой указатель, если открытие прошло успешно; и возвращает NULL, если произошла ошибка. Ошибка может возникать в следующих ситуациях:
-
не существует файла;
-
у программы недостаточно прав доступа для работы с файлом;
Для дальнейшей корректной работы следует писать примерно такой код:
if (f == NULL) {
// файл не удалось открыть
}
else {
// Работа с файлом
}
Допустим, что нам удалось открыть файл, т.е. f != NULL. Тогда для того, чтобы считывать файл, можно использовать функцию:
fscanf(f, "%s", ptr);
Эта функция работает аналогично функции scanf.
Поэтому использовать эту функцию небезопасно!
Все проблемы, перечисленные для scanf'а, имеют место и при работе с fscanf'ом.
Если мы хотим записать в файл что-то, то мы должны сначала открыть его на запись:
FILE *f = fopen("file2.html", "w");
Тут "w" означает, что мы открываем файл на запись (от write).
Если файл не существовал, то он создастся и откроется на запись, а если он существовал, то он сначала будет уничтожен, а затем создан заново, и потом файл будет открыт на запись.
Еще один способ открыть файл -- это открыть его на дозапись.
Это можно сделать с помощью параметра "a" (от append).
Если файл не существовал, то он создастся и откроется на запись, а если он существовал, то он откроется на запись, и запись будет производится в конец файла.
Затем можно использовать функцию fprintf(f, ...)
1.2.1 Зачем нужно закрывать файлы
-
Зададимся вопросом: "Что надо сделать после того, как мы поработали с файлом?"
Формальный ответ: "Закрыть файл." Это можно сделать с помощью функции:
fclose(f);
Но зачем это делать?
Ввиду механического устройства жесткого диска, данные в файл попадают не сразу.
Сначала данные записываются в так называемый буфер (область оперативной памяти), и когда он переполнится, то данные из буфера будут записаны в файл.
Такая схема придумана для ускорения работы с файлами.
На самом деле, буфер -- это поле структуры FILE: указатель на массив char'ов.
Если мы напишем fprintf(...), то запись произведется в буфер.
И только тогда, когда буфер будет заполнен до конца, он будет сразу весь записан на жесткий диск.
По этой причине, если мы не закроем файл функцией fclose(f), то последние данные из буфера не запишутся в файл.
Отсутствие этой команды может привести к потере данных в файле, который был открыт для записи (дозаписи).
-
А зачем закрывать файлы, открытые только на чтение?
Если не закрывать файлы (которые открыты даже для чтения), то это может привести к ограничению доступа к файлу для других программ.
Какие именно ограничения наложатся -- это зависит от ОС.
Но в ОС Windows если файл открыт на чтение и не закрывается, то из другой программы его нельзя удалить.
-
В любой ОС есть ограничение на количество одновременно открытых файлов.
И это еще одна причина для закрытия файлов.
1.2.2 Важность буфера при работе с файлами
-
Рассмотрим следующую ситуацию. Программа пишет протокол своих действий в файл (например, с помощью функции
fprintf).
Допустим, что программа сломалась. Понятно, что скорее всего получится так, что в файл последний fprintf (последний протокол действий) не запишется.
Причина тому -- это буфер.
Чтобы "протолкнуть" буфер в файл, используется функция
fflush(f)
В коде это выглядит примерно так:
fprintf(file, "%d", data); //данные записались в буфер
fflush(file); //данные из буфера "проталкнулись" в файл
1.3 Стандартные уже открытые файлы: stdin, stdout, stderr
С точки зрения UNIX клавиатура и экран -- это файлы.
Есть три стандартные константы:
FILE *stdin
FILE *stdout
FILE *stderr
Это три стандартных заранее открытых файла.
stdin -- это стандартный файл (поток) ввода, а stdout -- стандартный файл (поток) вывода. Таким образом:
scanf(...) в точности эквивалентно fscanf(stdin, ...)
printf(...) в точности эквивалентно fprintf(stdout, ...)
Такой гибкостью можно воспользоваться при написании программы для работы с файлами.
Например, для отладки программы можно выводить информацию на экран монитора, а не в файл.
Для этого в начале работы с файлом пишем две строчки:
//FILE *f = fopen(...);
FILE *f = stdin;
При этом код программы будет содержать такие функции: fscanf(f, ...) или fprintf(f, ...).
А когда отладка законичится, просто снимаем/ставим соответствующие комментарии в двух строчках программы.
stderr -- это стандартный файл (поток) ошибок. По умолчанию выводит данные на экран.
Но существует заметное отличие этого "файла" от stdin и stdout: stderr -- небуферизованный файл (поток).
Поэтому в этот файл (поток) все байты уходят без "задержки", которая могла бы возникнуть при буферизированном подходе.
Понятно, что польза от этого подхода заключается в том, что вместо кода:
fprintf(stdout, ...);
fflush(stdout);
мы пишем:
fprintf(stderr, ...);
1.4 Текстовые и бинарные файлы; что меняет опция t/b
Рассмотрим строку:
fopen(f, "file1.txt", "w");
Почему второй параметр "w" является строкой, а не символом?
На самом деле бывает много способов прочитать/записать файл. Например:
fopen("file1.txt", "wt") -- откроет файл как текстовый файл;
fopen("file1.txt", "wb") -- откроет файл как бинарный файл.
Но в чем отличие?
Разница заключается лишь в том, что символы переноса строк запишутся по разному.
Рассмотрим пример в UNIX и Windows:
Исходная строка кода выглядит так: fprintf("Hello\n");
-
Откроем в Windows файл на запись с параметром
"wb" (как бинарный файл).
Это означает, что в него запишется в точности то, что мы передали в функции fprintf.
Тогда в файл запишутся ровно 6 байт: Hello\10
-
А теперь мы откроем в Windows файл на запись с параметром
"wt" (как текстовый файл).
Тогда в файл запишутся ровно 7 байт: Hello\10\13
Тут \10\13 означает симлов перевода строки в ОС Windows.
-
Откроем в UNIX файл на запись с параметром
"wt" или "wb".
Тогда в файл запишутся ровно 6 байт: Hello\10
Тут \10 означает симлов перевода строки в ОС UNIX.
В ОС UNIX разницы все-таки нет.
Различие между "wt" и "wb" объясняется тем, что в разных операционных системах символы перевода строки разные.
При чтении файла, т.е. при открытии файла с параметрами "rt" или "rb", проблема следующая.
Если мы поставим параметр "rb", то при чтении файла символ \10 будет восприниматься как перевод строки.
А если поставим параметр "rt", то при чтении файла пара символов \10\13 будет восприниматься как символ перевода строки.
1.5 Как же читать/писать на самом деле: fgets, fread и fwrite
Использование функций ptintf и scanf для записи и для чтения -- это очень плохая идея.
Тогда все-таки как лучше читать и записывать?
Хороший способ чтения из файла дает функция fgets() (от "get string"):
char *fgets(char *buffer, size_t length, FILE *file);
Тут
-
buffer -- это указатель на буфер, в который мы читаем;
-
length -- это размер буфера;
-
file -- это файл, из которого мы читаем (если читаем с клавиатуры, то разумно использовать stdin).
-
Функция возвращает строку
Эта функция делает примерно следующее. Она читает из файла file в буфер buffer не больше length-1 символов.
Функция может прочитать не все length-1 символов в том случае, если она встретит конец строки, либо конец файла.
Функция читает length-1 символ потому, что последний символ функция добавляет сама -- '\0'
Налицо быстрота и безопасность.
Главное отличие от scanf'а заключается в том, что функция перестанет читать в тот момент, когда закончится буфер.
Быстрота обусловлена тем, что функция scanf должна в момент выполнения разобрать форматную строку,
в то время как fgets просто читает строку.
1.5.1 Как доставать числа? Семейство atoi, sscanf
В то время как фунция fgets читеат обычную строку, функция scanf может читать и различные другие типы (целые, вещественные числа).
В языке C есть семейство функций ~ atoi (a -- ASCII, i -- integer):
N = atoi(string);
Функция принимает единственный параметр строку и пытается ее привести в типу int.
Надо заметить, что функция atoi безопасная, но не очень удобная. Безопасная в том смысле, что не сломается: atoi("25a") == 25.
"Неудобства" заключаются в том, то если мы передаем в качестве параметра строку, в которой есть не только числа, нужно быть очень внимательным и знать, как работает эта функция.
Функция atoi никак не проинформирует нас, если преобразование прошло неудачно.
Например, atoi("abc") == 0, что на самом деле не совсем соостветствует действительности.
Использовать функцию atoi нужно лишь в том случае, когда вы уверены, что в строке есть число.
Родственные функции: atol, atoll, atof, strtol.
Им соответствуют функции для преобразования в типы long, long long и float.
Рассмотрим подробнее strtol:
long strtol(char *buffer, char **endPtr, int base);
Тут
-
buffer -- это указатель на буфер, из которого мы читаем;
-
endPtr -- это переменная, которая используется для того, чтобы сообщить нам насколько успешно произошло преобразование;
это указатель на char *, в котором записан первый символ, который не смог проинтерпретироваться с помощью функции strtol;
Применение выглядит примерно так:
char *end;
char *ptr = "25a";
int N = strtol(ptr, &end, 10);
Теперь end указывает на "a".
if (ptr == end) {
// ничего не получилось прочитать
}
-
base -- это основание системы счисления, с которой мы работаем (от 2 до 36);
-
Функция возвращает целое число типа
long.
Более мощное средство
Есть более мощное средство, чем нежели fgets + atoi. Речь идет о функции sscanf.
Вместо использования функции fscanf(f, "%d", &N) можно использовать связку:
fgets(ptr, 100, f);
sscanf(ptr, "%d", &N);
В чем преимущество и мощность такого подхода?
-
Мы знаем длину того, что мы прочитали;
-
Рассмотрим следующую ситуацию: мы хотим прочитать какие-то данные, но не смогли из-за ошибки.
Используя такой подход, мы можем передать пользователю сообщение об ошибке и ту строчку, которую нам не удалось прочитать: ptr.
С использованием fscanf'а это невозможно.
С помощью fscanf'а мы можем только узнать, сколько переменных было успешно прочитан.
А именно: посмотреть на возвращаемое значение.
При таком подходе, осталась невысокая скорость работы, однако надежность есть.
1.5.2 fread и fwrite
На самом деле не все файлы выглядят как текст. Файле могут быть записаны числовые данные.
size_t fread(void *ptr, size_t size, size_t nelts, FILE *f);
-
void *ptr -- указатель на ту область памяти, в которую мы читаем;
-
size_t size -- размер элемента, который мы читаем;
-
size_t nelts -- максимальное количество элементов, которые можно записать;
-
FILE *f -- файл, из которого читаем;
-
size_t fread() -- сама функция возвращает количество элементов, которые удалось прочитать.
Есть парная функция:
size_t fwrite(const void *ptr, size_t size, size_t nelts, FILE *F);
Аналогично fread эта функция возвращает количество элементов, которые удалось записать.
Тут параметр nelts просто показывает, сколько элементов надо вывести.
1.6 Другие полезные опции: fseek и ftell
Для файлов, которые открыты на чтение есть полезные функции. Одна из них это:
int fseek(FILE *f, long offset, int flag);
-
FILE *f -- файл, в котором передвигаемся;
-
long offset -- количество байтов для отступа, отступ производится в соответствии с 3-м параметром;
-
int flag -- позиция, от которой будет совершен отступ; в стандартной библиотеке C для этого параметра определены 3 константы:
SEEK_SET -- начало файла;
SEEK_CUR -- текущас позиция;
SEEK_END -- конец файла;
-
int fseek() -- сама функция возвращает ноль, если операция прошло успешно, иначе возвращается ненулевое значение.
Еще одна полезная функция может определить текущее положение в файле (который открыт для чтения):
long int ftell(FILE *f);
2 Другие подходы для работы с файлами
2.1 File descriptors. Open, close, read, write
В языке C есть много способов работы с файлами. Помимо структуры FILE можно использовать так называемые дескрипторы файла (file descriptors).
Дескриптор файла -- целое неотрицательное число.
Оно обозначает номер открытого файла в таблице открытых файлов операционной системы.
Использование дескрипторов файла -- более низкий уровень, чем нежели ипользование струкруты FILE.
Структура FILE -- сущность языка C и его стандартной библиотеки, тогда как дескриптор файла -- сущность операционной системы.
Например, при работе со структурой FILE автоматически создается буфер, и программист работает с более высокоуровневой абстракцией.
А при работе с дескрипторами файла программист должен позаботится о буферизации вручную.
Пример работы с дескрипторами файла довольно прост и почти в точности повторяет процесс работы со структурой FILE:
int fd = open("...");
Сходство работы с дескрипторами файла с работой со структурой FILE заключается в том, что в названии функций отсутствует буква "f".
Иногда параметры функций незначительно отличаются.
Структуру FILE полезно использовать при работе с настоящими "файлами" (которые находятся на жестком диске).
Ипользовать дескрипторы файла полезно в случаях работы со специальными "файлами".
В этом подходе есть своя специфика работы, но сейчас просто полезно знать, что такой подход существует.
Аналогами stdin, stdout и stderr в дескрипторах файла являются числа 0, 1 и 2 соответственно.
Стандарт POSIX.1 обозначил числа 0, 1, 2 символическими константами STDIN_FILENO, STDOUT_FILENO и STDERR_FILENO соответственно.
2.2 Memory mapping. Что делает mmap
Следующий способ работы с файлами удобен в тех случаях, когда приходится читать файл нелинейно: надо "ходить" вперед и назад.
В предыдущих подходах такие ситуации оказывались неудобными с точки зрения программирования: получился бы громоздкий код.
В языке C был придуман удобный способ работы в таких ситуациях, который называется memory mapping. Соответствующая функция:
char *ptr = mmap("...");
Работает эта функция примерно так.
Мы указываем этой функции файл на диске, и она "отображает" этот файл в такую-то область в памяти.
В результате работы функции мы получаем указатель на начало файла. И потом мы можем работать с этим файлом как с обычным указателем на какую-то область памяти: можем "ходить" вперед и назад по этому файлу.
Можно "отобразить" не весь файл целиком, а, например, отдельную часть файла: с 3-его килобайта по 4-ый килобайт.
2.3 Win32 API: FileCreate, FileRead, etc.
При работе с файлами в ОС Windows можно использовать все те функции, которые были описаны выше.
В ОС Windows есть своя большая стандартная библиотека Win32 API.
В этой библиотеке также есть функции для работы с файлами: например, функции FileCreate(...) или FileOpen(...).
Они по своей работе похожи на функции из стандартной библиотеки C, но отличия также присутствуют.
Они заключаются в параметрах этих функций и небольших "хитростях", которые мы здесь опустим.
Если вы программируете под ОС Windows и пишите программу для работы в ОС Windows, то стоит пользоваться библиотекой Win32 API для работы с файлами.
3 Ввод и вывод в языке C++, потоки
В языке C++ объекты для работы с файлами называются потоками (streams).
В данном случае слово "поток" означает то же самое, что и "файл" в языке C.
Классы для работы с файлами в языке C++ называются std::istream и std::ostream для ввода и вывода соответственно.
3.1 Глобальные переменные std::cout, std::cin, std::cerr
В header'е <iostream> объявлена глобальная переменная std::cout; она используется как стандартный поток вывода на экран.
Эта переменная является объектом класса std::ostream.
В этом классе есть перегруженный оператор <<, который выводит на экран:
std::cout << 1;
В данном случае на экран будет выведена единица.
Аналогично можно выводить переменные: std::cout << N;
В данном случае переменная N (целое число) будет выведена на экран в естественной форме.
Это можно переписать аналогично через printf():
printf("%d", N);
Еще в header'е <iostream> объявлены переменные std::cin и std::cerr для стандартного потока ввода и потока ошибок соответственно.
Они являются объектами классов std::istream и std::ostream соотсветственно.
Аналогично тому, как stderr отличается от stdin, в языке C++ std::cerr отличается от std::cout отсутствием буферизации.
В классе std::istream есть перегруженный оператор >>.
Можно считывать информацию из стандартного потока ввода (с клавиатуры).
3.2 Форматированный вывод возможен: std::ios::hex
Возможен ли форматированный вывод, которым мы пользовались в языке C фунцией printf()?
Наример, как вывести ту же переменную N в 16-ой записи?
В языке C++ форматированный вывод возможен при помощи вывода на экран специальной управляющей команды:
std::cout << std::ios::hex << N;
В точности то же самое выведет команда printf("%x", N);
Чтобы не писать перед кажой переменной ее формат, можно использовать функцию:
std::cout.setf(std::ios::hex);
Она установит формат вывода в стандартный поток вывода на экран.
Этот подход настолько же мощный, как и использование форматной печати с помощью printf.
3.3 Операторы << и >>
Давайте рассмотрим более подробно опрератор <<.
В рассмотренном ранее случае синтаксис такой:
std::ostream &operator << (std::ostream &os, int N);
-
&os -- поток, в который мы будем выводить;
-
N -- переменная, которую мы будем выводить;
-
Оператор возвращает ссылку на поток, в результате чего можно писать так:
std::cout << N << M;
В общем случае вторым параметром может быть любой стандартный тип.
Это связано с тем, что этот оператор был перегружен для всех стандартных типов языка C++.
В случае оператора >> все аналогично.
Если хочется написать свой оператор <<, то нужно переопределить этот оператор в своем классе.
Если у нас есть класс комплексных чисел Complex, то вывод этих чисел через оператор << надо написать всего один раз на все случаи (экран, файл, принтер ...)
3.4 Работа с файлами
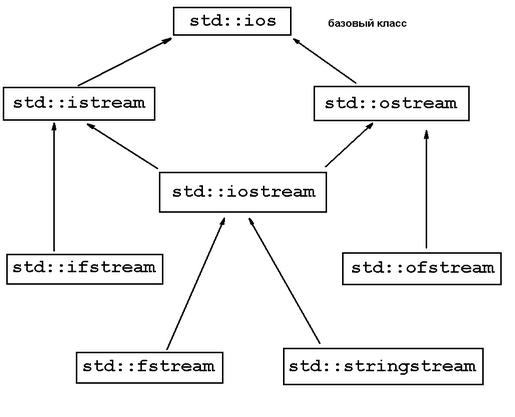
Классами для работы с файлами в языке C++ являются ifstream, ofstream и fstream.
Код для открытия файла и его чтения выглядит примерно так:
ifstream ifs;
ifs.open("file1.txt");
// далее с помощью оператора >> можно читать из файла, если он успешно открылся;
Аналогично можно использовать конструктор с параметром: ifs("file1.txt"); после чего создается объект и открывается по возможности файл.
В классе istream есть метод close(), который закрывает файл (на подобие работы с файлами в языке C).
Однако вызывать этот метод необязательно. Дело в том, что в деструкторе класса этот метод вызовется автоматически.
Работа с объектами классов ofstream и ofstream и fstream осуществляется по аналогичному сценарию.
3.5 Класс stringstream
Класс stringstream наследуется от iostream.
Используется этот для класс для следующих целей. Если мы хотим выводить комплексные числа не только на экран или в файл, но и в окно какой-нибудь программы (GUI), то как использовать stringstream?
При этом мы не хотим писать один и тот же код программы.
Можно просто печатать в строку с помощью stringstream.
3.6 Иерархия классов
4 Общий совет
Общий совет заключается в том, что не надо смешивать техники для работы с файлами.
Например, не надо в одной и той же программе использовать функции из стандартной библиотеки C (fread/fwrite) и классы-потоки из языка C++ (istream/ostream).